LLM & GPT Integration Services
Enterprise LLM Integration
We integrate large language models, OpenAI GPT, Anthropic Claude, Google Gemini, and open-source alternatives, into your existing applications and workflows with proper prompt engineering, safety guardrails, and production monitoring.

Production-Ready LLM Integration for Your Business
Integrating LLMs into production applications requires more than API calls. We handle the full complexity, prompt engineering, response validation, rate limiting, cost optimisation, fallback strategies, and monitoring, ensuring your LLM integration is reliable, safe, and production-ready.



Proven Success with Data Driven Design, Development and Digital Marketing.

505%
In Organic Traffic In 3 Months From
17k+
Organic Users Within 12 Months

120%
Increase In Enquiries
730%
Increase In Organic Traffic In 3 Months

+110%
Organic Traffic Uplift Within 3 Months Post-Launch
+65%
Increase In Conversion Rate Across Service Pages
1,600%
Return On Investment On Facebook Ads
860%
Increase In Organic Traffic From Google

68.43%
Decreased BounceRate Of New Website
41.61%
Increased Monthly Impressions
505%
In Organic Traffic In 3 Months From
17k+
Organic Users Within 12 Months
120%
Increase In Enquiries
730%
Increase In Organic Traffic In 3 Months
+110%
Organic Traffic Uplift Within 3 Months Post-Launch
+65%
Increase In Conversion Rate Across Service Pages
1,600%
Return On Investment On Facebook Ads
860%
Increase In Organic Traffic From Google
68.43%
Decreased BounceRate Of New Website
41.61%
Increased Monthly Impressions
505%
In Organic Traffic In 3 Months From
17k+
Organic Users Within 12 Months
120%
Increase In Enquiries
730%
Increase In Organic Traffic In 3 Months
+110%
Organic Traffic Uplift Within 3 Months Post-Launch
+65%
Increase In Conversion Rate Across Service Pages
1,600%
Return On Investment On Facebook Ads
860%
Increase In Organic Traffic From Google
68.43%
Decreased BounceRate Of New Website
41.61%
Increased Monthly Impressions




















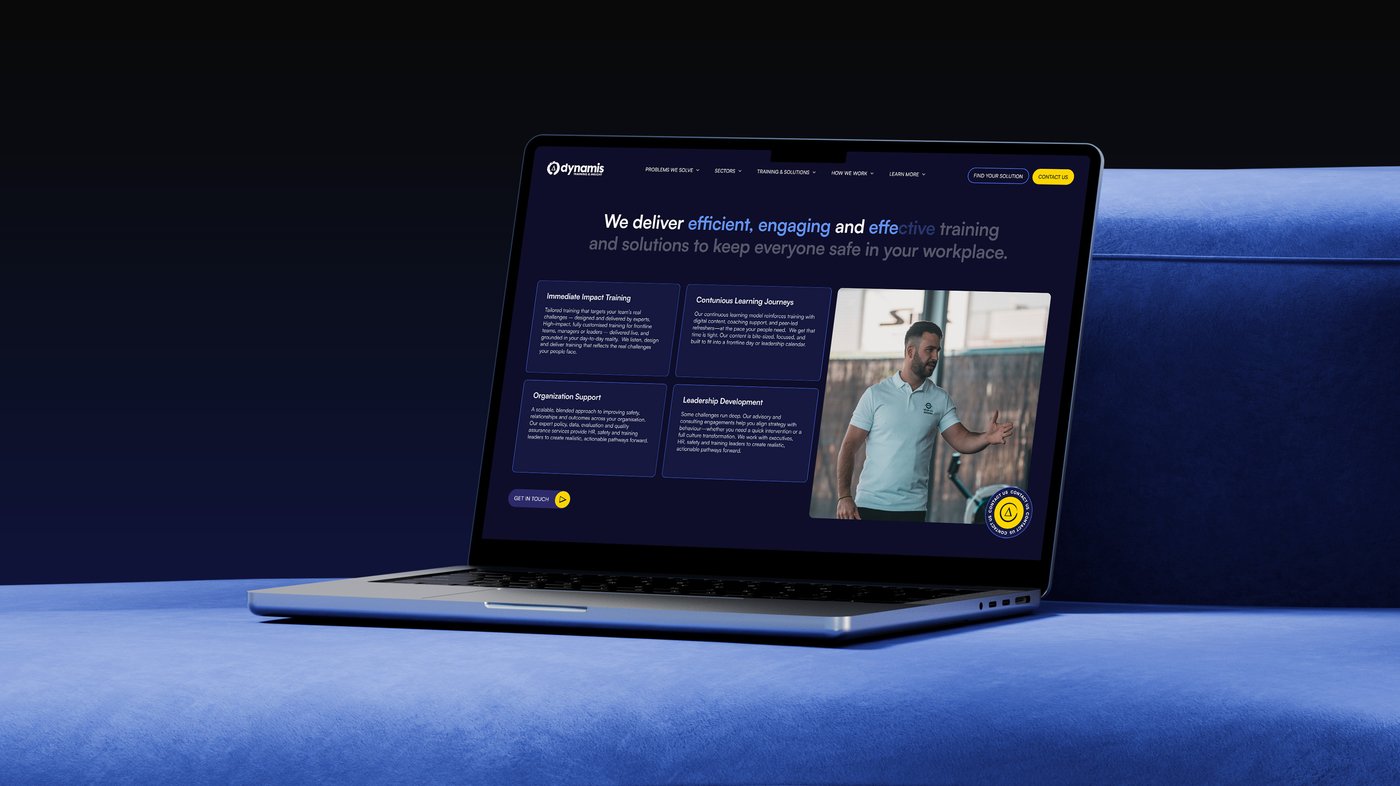
Service Features
What Our Clients Say About Us

“I can highly recommend Atomic. We have been working with Atomic for some time now. They have designed and created 5 fantastic websites for us, with a complex back end system for our users, as well as some custom event software our users are able to utilize for our corporate events. We are now also in the final stages of launching apps through Atomic.”

“Obviously, the results are the most important thing for us, but so too has been their commitment and enthusiasm. It's clear they are committed and determined to deliver above and beyond expectations. Their overall style is highly collaborative. We have had weekly, online meetings with no less than 3 Atomic consultants present on each call.”

“We have noticed a marked increase in online bookings and enquiries for the events space. We have had lots of comments from customers saying how inviting the site is now, and how easy it is to navigate and make a booking. We were frequently updated by Timothy, who gave us lots of advice and guidance on design and always made himself available for any queries.”

“Our ROAS for our Facebook and Instagram campaigns has averaged around 4-6 with highs of 15 during peak selling time. Previously we had been seeing 0.5-2 with our own marketing. We were impressed with the way they really learnt to understand our business. Though it's likely different to any previous business model they have worked with.”

“I approached Atomic Digital Marketing to modernise and SEO optimise my old dinosaur of a web site. They firstly UX/UI designed and prototyped my new website and then built the entire thing within two months. Not only am i absolutely thrilled with the outcome of what they have produced, so too are my clients.”

“I needed to rebrand my website and Atomic handled the job very quickly, efficiently and without needing much from me which was great. It's very nice to work with a business that you feel has complete control of the work required - especially when you don't understand it yourself.”

“We have been working with Atomic now for over 6 months. They have built a new website, run our CPC and organics. So far so great and we have achieved all that we set out to do. Recommended!”

“The team did a great job at building a website for our first aid training business. I'd recommend Atomic to anyone looking for a good design which also has a focus on SEO site structure.”

“I always doubt the claims of 3rd party tech agencies but received 1st class, rapid service that was right on price and exceeded the deliverables that we had agreed with them. Atomic Marketing know their stuff and delivered for Evolution Power Tools. Easy to work with, quick to respond and exceeded our expectations. That doesn't happen often.”

“Atomic Digital Marketing helped the client generate leads and referral customers. The team was always available for any questions and calls to discuss elements of the website build. They used Agile methodology to iterate quickly and provide guidance on the UX experience. Tim, Justin, Robyn & Peter were always on hand to help.”

“We have been working with Atomic for the first half of the year now, and have offered a fantastic service, extremely knowledgeable and up to date with the latest marketing trends. Very tailored made to our company needs, and always very quick to respond! just a great team all round!!”

“As managing director at Enbi Global, it was made known to me that our SEO was suffering heavily. Atomic first conducted a site SEO audit which identified where our issues lay, and then subsequently worked on the website for the following week ironing these issues out. Following the work, our site optimisation score increased to around 94% and our rankings continued to improve.”
What Our Clients Say About Us
Our Process
Requirements & Evaluation
We define your LLM requirements, accuracy, latency, cost targets, privacy constraints, and evaluate models from OpenAI, Anthropic, Google, and open-source options.
Prompt Engineering
We design, test, and optimise prompt templates for your use cases, building a library of reliable prompts that produce consistent, high-quality outputs.
Safety & Guardrails
We implement input validation, output filtering, content moderation, and structured output enforcement to ensure safe, predictable behaviour.
Integration Build
We build the integration layer, API clients, caching, rate limiting, retry logic, fallback strategies, and error handling for production reliability.
Testing & Evaluation
We run comprehensive evaluations against test datasets, edge cases, adversarial inputs, and performance benchmarks before production deployment.
Monitor & Optimise
We deploy with monitoring for quality, cost, latency, and safety metrics, continuously optimising prompts and model selection based on real usage.
Our Process







Requirements & Evaluation
We define your LLM requirements, accuracy, latency, cost targets, privacy constraints, and evaluate models from OpenAI, Anthropic, Google, and open-source options.
Prompt Engineering
We design, test, and optimise prompt templates for your use cases, building a library of reliable prompts that produce consistent, high-quality outputs.
Safety & Guardrails
We implement input validation, output filtering, content moderation, and structured output enforcement to ensure safe, predictable behaviour.
Integration Build
We build the integration layer, API clients, caching, rate limiting, retry logic, fallback strategies, and error handling for production reliability.
Testing & Evaluation
We run comprehensive evaluations against test datasets, edge cases, adversarial inputs, and performance benchmarks before production deployment.
Monitor & Optimise
We deploy with monitoring for quality, cost, latency, and safety metrics, continuously optimising prompts and model selection based on real usage.
Featured Work
Featured Work
Featured Work

Featured Work
Featured Work
Featured Work
Featured Work
Featured Work
Featured Work
Featured Work
Featured Work
Featured Work
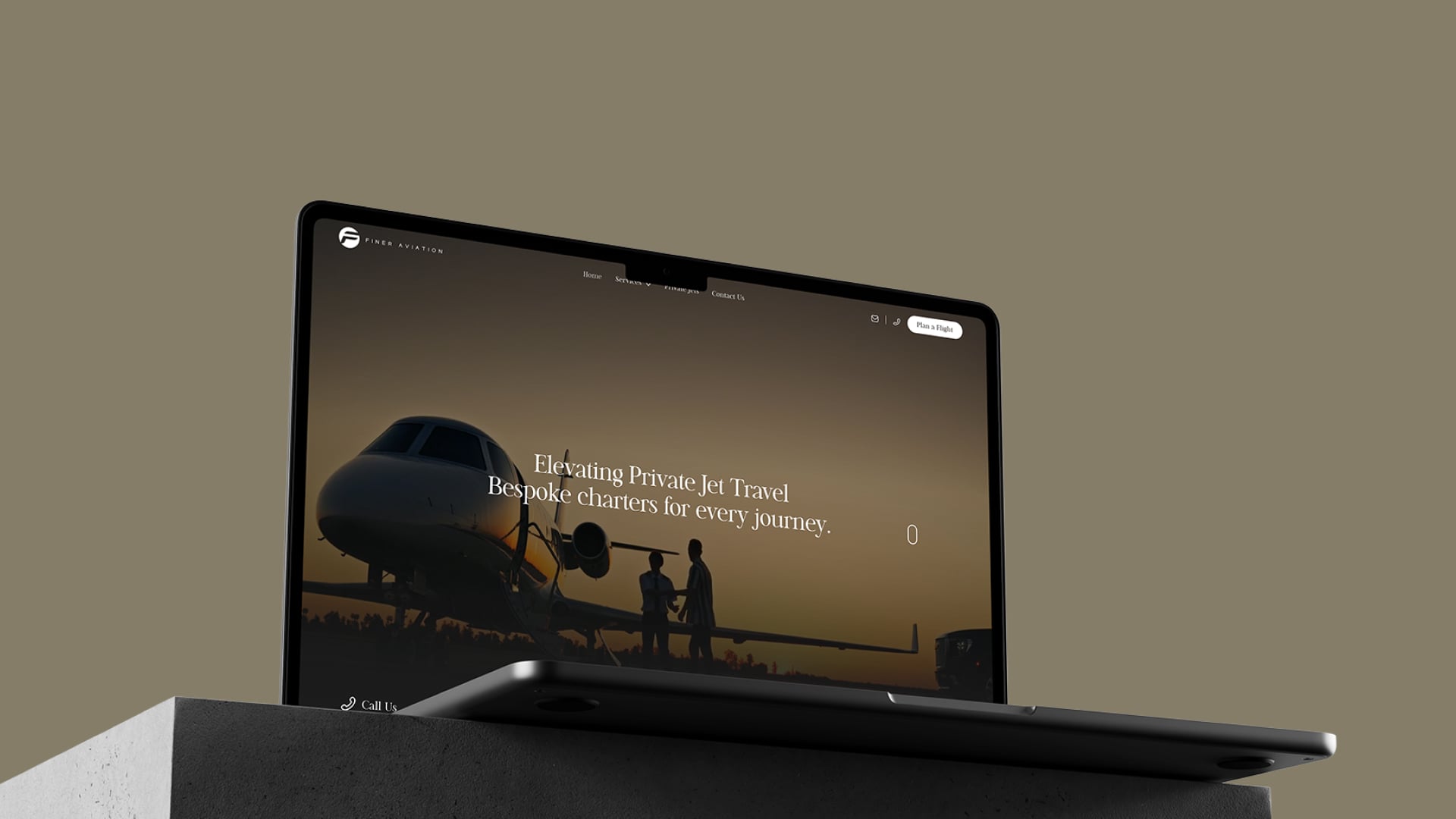
Finer Aviation
A global private jet charter provider needed a premium website to enhance credibility, improve user experience, and streamline inquiries.
View ProjectClarks
The client, Clarks - a globally recognised footwear brand, needed a digital gift card solution that could be accessed via QR code and stored in mobile wallets, ready for use across multiple markets and platforms.
View ProjectFAQs
It depends on your requirements. GPT-4o offers excellent general performance. Claude excels at long documents and careful reasoning. Gemini is strong for multimodal tasks. Open-source models (Llama, Mistral) offer full control and can be cheaper at scale. We evaluate each against your specific needs.
We implement multiple cost optimisation strategies, prompt compression, response caching, intelligent model routing (using cheaper models for simple tasks), batching requests, and monitoring token usage. Most clients see 40-60% cost reduction versus naive API usage.
We implement strict data handling, PII stripping before API calls, enterprise data agreements with providers (preventing training on your data), and the option to run open-source models on your own infrastructure for maximum control.
Yes. We design LLM integration as a service layer that connects to your existing application via APIs. This means minimal changes to your current codebase while adding powerful AI capabilities, summarisation, classification, generation, search, and more.